集合
ArrayList类(单列集合)-List接口
//main
List list = new ArrayList();
//add:添加单个元素
list.add("jack");
list.add(10);//list.add( new Integer(10))
list.add(true);
//remove:删除指定元素
list.remove(0);//删除第一个元素
list.remove(true);//指定删除某个元素
//contains:查找元素是否存在
System.out.println(list.contains("jack"));//T
//size:获取元素个数
System.out.println(list.size());//2
//isEmpty:判断是否为空
System.out.println(list.isEmpty());//F
//clear:清空
list.clear();
//addAll:添加多个元素(放一个集合进去)
ArrayList list2 = new ArrayList();
list2.add("123");
list2.add("789");
list.addALL(list2);
System.out.println(list);
//containsAll:查找多个元素是否都存在
//remove:删除多个元素
细节
- ArrayList可以加入null, 并且多个
- ArrayList是由数组来实现数据存储的
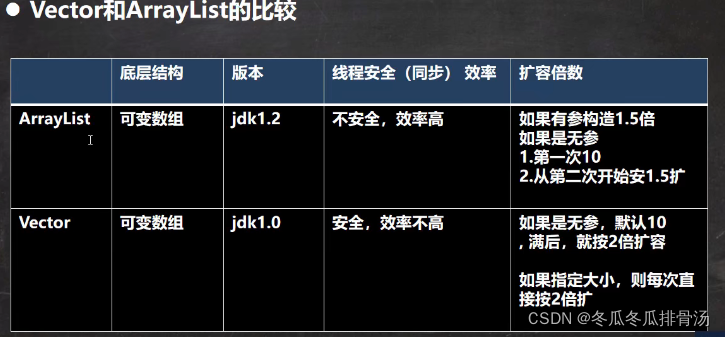
- ArrayList基本等同于Vector, 除了ArrayList是线程不安全的(执行效率高), 在多线程情况下, 不建议使用ArrayList
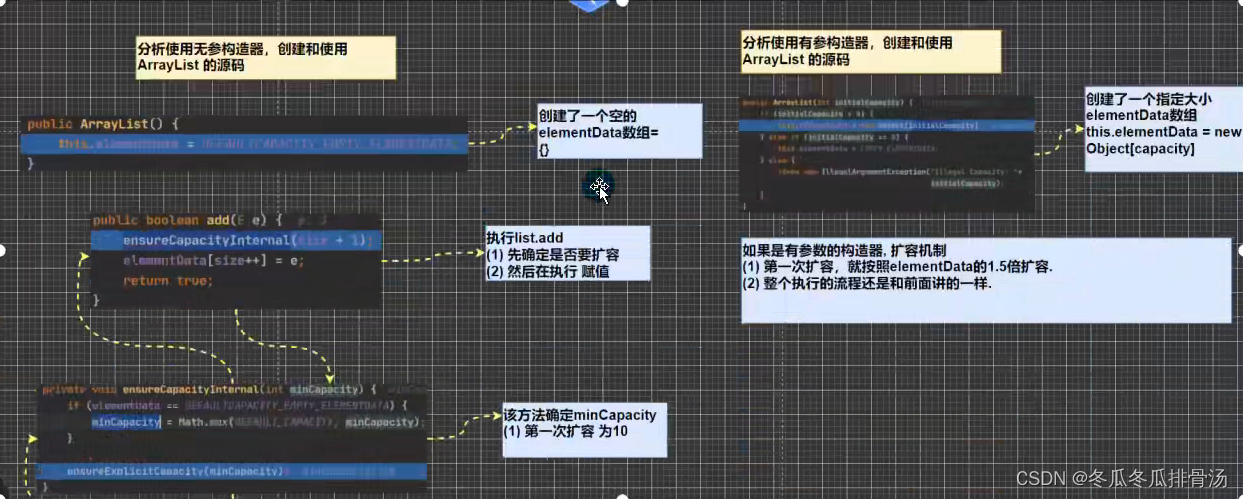
ArrayList扩容机制
- ArrayList中维护了一个Object类型的数组elementData
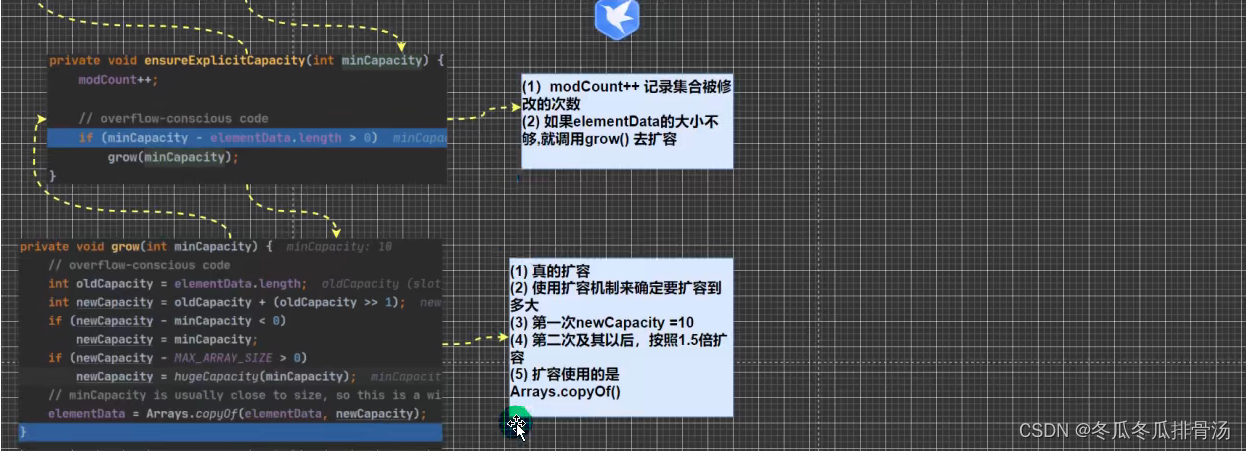
- 当创建ArrayList对象时, 如果使用的是无参构造器, 则初始elementData容量为0, 第一次添加, 则扩容elementData为10, 如需要再次扩容, 则扩容elementData为1.5倍
- 如果使用的是指定大小的构造器, 则初始elementData容量为指定大小, 如果需要扩容, 则直接扩容elementData为1.5倍
每次都要去检测要不要扩容, 所以效率不高
Vector类
- Vector底层也是一个对象数组
- Vector是线程同步的, 即线程安全
- 在开发中, 需要线程同步安全时, 考虑使用Vector
LinkedList类
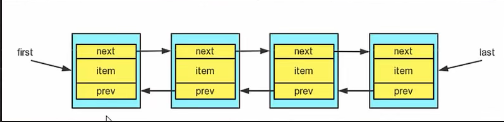
- LinkedList底层实现了双向链表和双端队列特点
- 可以添加任意元素(元素可以重复), 包括null
- 线程不安全, 没有实现同步
LinkedList底层机制
- LinkedList底层维护了一个双向链表
- LinkedList中维护了两个属性first和last分别指向 首节点和尾节点
- 每个节点(Node对象), 里面维护了prev, next, item三个属性, 其中通过prev指向前一个, 通过next指向后一个节点, 最终实现双向链表
- LinkedList的元素的添加和删除, 不是通过数组完成的, 相对来说效率较高
List集合选择
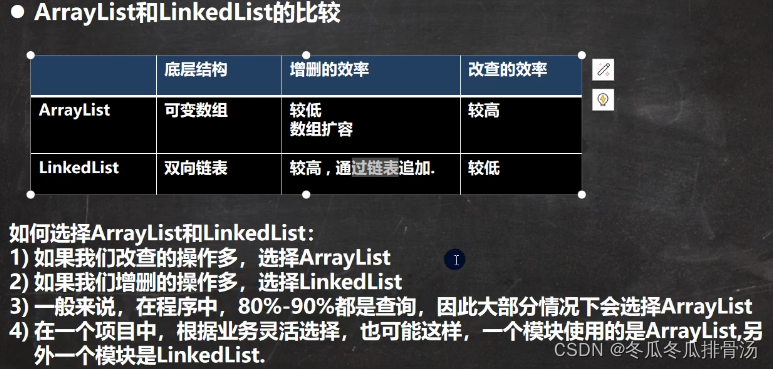
迭代器遍历
Iterator对象称为迭代器, 主要用于遍历Collection集合中的元素. 所以实现了Collection接口的集合类都有一个Iterator()方法. Iterator仅用于遍历集合, Iterator本身并不存放对象
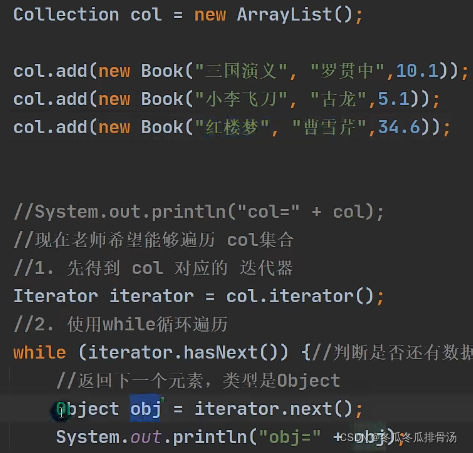
细节
- 当退出while循环后, 这时iterator迭代器, 指向最后的元素
- 如果接着指向
iterator.next();会报错 : NoSuchElementException - 如果希望再次遍历, 需要重置迭代器
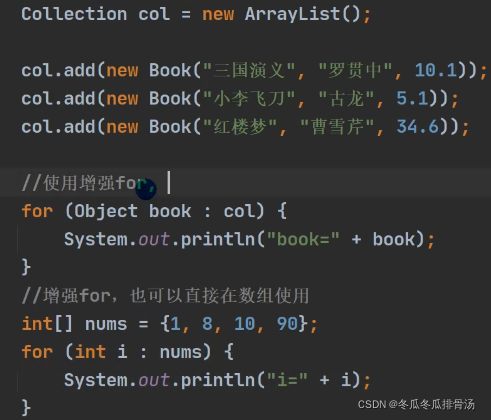
增强for循环
Set接口
也是双列集合, 但是和Map不同的是, 他的 [K, V] 中的V是一个常量present
- set 接口的实现类的对象(Set接口对象), 不能存放重复的元素, 可以添加一个null
- set 接口对象存放数据是无序的(即添加的顺序和取出的顺序不一致)
- 取出的顺序的顺序虽然不是添加的顺序, 但是它是固定的
- 遍历
- 方式一 : 使用迭代器
- 方式二 : 增强for
- 不能通过索引的方式来获取, (不能用普通的for来遍历)
HashSet类
- HashSet实际上是HashMap
- 可以存放null值, 但是只能有一个null
- HashSet不保证元素是有序的, 取决于hash后, 再确定索引的结果
- 不能有重复元素/对象
经典面试题
set = new HashSet();
//HashSet 不能添加相同的元素/对象
set.add(new Dog("tom"));//OK
set.add(new Dog("tom"));//OK
set.add(new String("jack"));//ok
set.add(new String("jack"));//加入不了
//为什么添加不了,通过底层机制说明
//hash() + equals()都相同的时候放弃加入
class Dog{
private String name;
public Dog(String name){
this.name = name;
}
}
HashSet底层机制
- HashSet底层是HashMap
- 添加一个元素时, 先得到hash值 - 转成 - 索引值
- 找到存储数据表table, 看这个索引位置是否已经存放元素了
- 如果没有, 直接加入
- 如果有, 调用equals比较, 如果相同, 就放弃添加, 如果不相同, 则添加到最后
- 在Java8中, 如果一条链表的元素大于等于 TREEIFY_THRESHOLD(默认是8) 并且table的大小 大于等于 MIN_TREEIFY_CAPACITY(默认是64), 就会进行树化(红黑树), 否则仍然采用数组扩容机制
HashSet扩容机制
HashSet底层是HashMap, 第一次添加时, table数组扩容到16, 临界值(threshold) 是 16*加载因子(loadFactor) 是0.75 = 12
如果table数组使用到了临界值12, 就会扩容到16 * 2 = 32, 新的临界值就是32 * 0.75 =24, 依次类推
注意 :
当我们向HashSet增加了一个元素, Node - 加入table, 就算是增加了一个 size++
LinkedHashSet类
LinkedHashSet 是 HashSet的子类
LinkedHashSet 底层是一个LinkedHashMap, 底层维护了一个数组 + 双向链表
LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置, 同时使用链表维护元素的次序, 这使得元素看起来是以插入顺序保存的
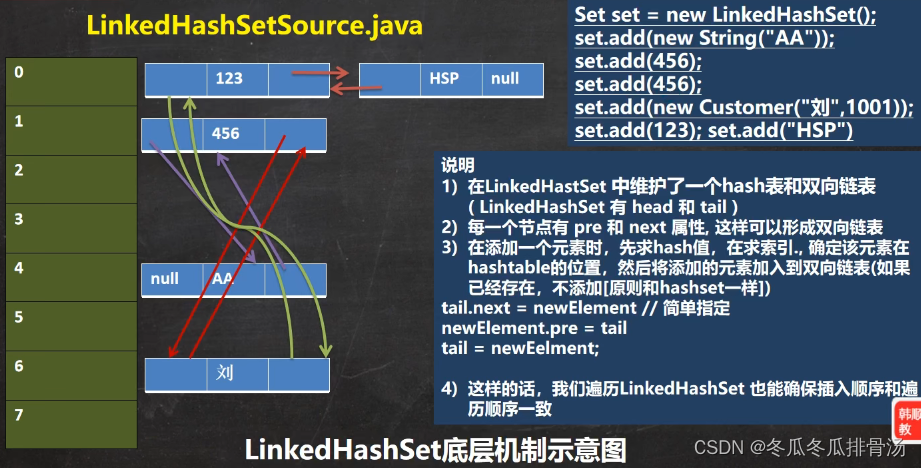
LinkedHashSet 不允许添加重复的元素
Map接口(双列集合)
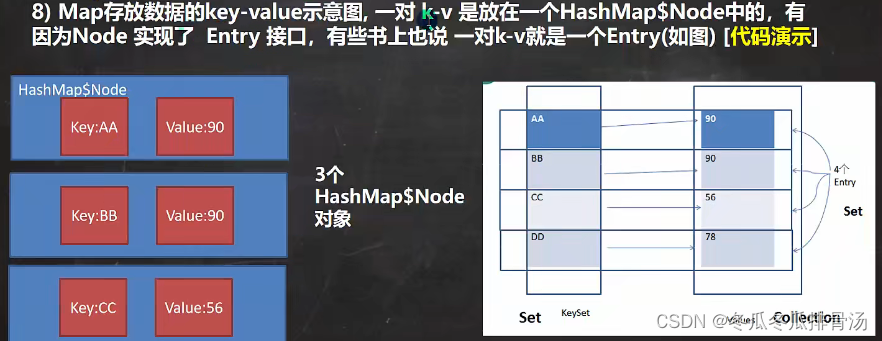
- Map 与 Collection 并列存在. Map 用于保存具有映射关系的数据 : Key - Value(双列元素)
- Map中的key 和 value 可以是任何引用类型的数据, 会封装到HashMap$Node对象中
- Map中的 key 不允许重复, 原因和HashSet一样, 如果重复了, 会进行替换原有的值
- Map中的 value 可以重复
- Map的 key 可以为null, value 也可以为null, 但是注意 key 只能有一个null, value 可以有多个null
- 常用String类作为Map的 key
- key 和 value 之间存在单向一对一关系, 即通过指定的 key 总能找到对应的 value
//main中
Map map = new HashMap();
//添加元素
map.put("no1","张无忌");
map.put("no2","jack");//无序的
//获取key对应的value
map.get("no2");
//删除
map.remove("no1");
//获取元素个数
map.size();
//判断个数是否为0
map.isEmpty();
//清除
map.clear();
//查找key是否存在
containsKey("no2");
Map接口遍历
/*
1.containsKey : 查找键是否存在
2.keySet : 获取所有的键
3.entrySet : 获取所有关系k-v
4.values : 获取所有的值
**/
Map map = new HashMap();
map.put(1,"123");
map.put(2,"qwe");
map.put(3,"asd");
map.put(4,"zxc");
//方式一 先取出所有的key, 通过key取出对应的value
Set keyset = map.keySet();
//1.增强for
for(Object key : keyset){
System.out.println(map.get(key));
}
//2.迭代器
Iterator iterator = keyset.iterator();
while(iterator.hasNext()){
Object key = iterator.next();
System.out.println(map.get(key));
}
//方式二 把所有的values取出
Collection values = map.values();
//1.增强for
for(Object value : values){
System.out.println(value);
}
//2.迭代器
Iterator iterator2 = values.iterator();
while(iterator2.hasNext()){
Object value = iterator2.next();
System.out.println(value);
}
//方式三 通过EntrySet 来获取k-v
Set entrySet = map.entrySet();//EntrySet<Entry<K,V>>
//1.增强for
for(Object entry : entrySet){
//将entry转成 Map.Entry
Map.Entry m = (Map.Entry)entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//2.迭代器
Iterator iterator3 = entrySet.iterator();
while(iterator3.hasNext()){
Object next = iterator3.next();
System.out.println(next.getClass());//HashMap$Node -实现-> Map.Entry (getKey, getValue)
//向下转型 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
HashMap类
- 小结
- HashMap是Map接口使用频率最高的实现类
- HashMap是以 key - val 对的方式来存储数据(HashMap$Node类型)
- key不能重复, 但是val可以重复, 允许使用null键和null值
- 如果添加相同的key, 则会覆盖原来的key - val, 等同于修改(key不会替换, val会替换)
- 与HashSet一样, 不能保证映射的顺序, 因为底层是以hash表的方式来存储
- HashMap没有实现同步, 因此是线程不安全的
- jdk8底层是 数组+链表+红黑树
- 扩容机制和 HashSet 相同
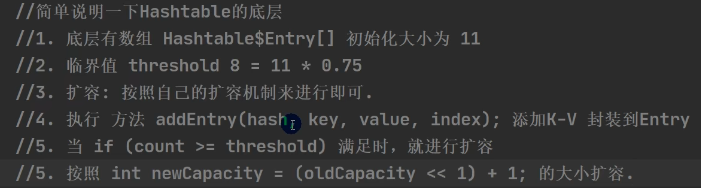
HashTable类
- 存放的元素是键值对 : 即 K-V
- hashtable的键和值都不能为null, 否则会抛出NullPointerException
- hashtable使用方法基本和HashMap一样
- hashtable是线程安全的, HashMap是线程不安全的
底层 : 扩容机制
Properties类
- Properties类继承自HashTable类, 并且实现了Map接口, 也是使用一种键值对的形式来保存数据
- 使用特点和HashTable类似
- Properties 还可以用于从 xxx.properties 文件中, 加载数据到Properties类对象, 并进行读取和修改
- xxx.properties 文件通常作为配置文件
集合的选择

比较器Comparator
TreeSet treeSet = new TreeSet(new Comparator(){
@Override
public int compare(Object o1, Object o2){
//下面调用String的comparaTo方法进行字符串大小比较
return ((String) o1).compareTo((String) o2);
}
});
//添加数据
treeSet.add("jack");
treeSet.add("tom");
treeSet.add("z");
treeSet.add("a");
//底层机制
//1.构造器把传入的比较器对象, 赋给了TreeSet的底层 TreeMap的属性this.comparator
//2.在调用 treeSet.add("tom"), 在底层会执行到
Comparator<? super K> cpr = comparator;
if(cpr != null){//cpr 就是我们的匿名内部类(对象)
do{
parent = t;
//动态绑定到我们的匿名内部类(对象)compare
cmp = cpr.compare(key, t.key);
if(cmp < 0)
t = t.left;
else if(cmp > 0)
t = t.right;
else //如果相等,即返回0,这个key就没有加入
return t.setValue(value);
}while(t != null);
}
泛型
泛型的理解和好处
使用传统方法的问题分析
- 不能对加入到集合ArrayList中的数据类型进行约束(不安全)
- 遍历的时候, 需要进行类型转换, 如果集合中的数据量较大, 对效率有影响
泛型的细节
泛型的作用是 : 可以在类声明时通过一个标识表示类中某个属性的类型, 或者是某个方法的返回值的类型, 或者是参数类型
//main中 Person<String> stringPerson = new Person<String>("jack"); class Person<E> { E s;//E表示 s的数据类型, 该数据类型在定义Person对象的时候指定,即在编译期间,就确定E是什么类型 public Person(E s){//E也可以是参数类型 this.s = s; } public E f(){//返回类型使用E return s; } }interface List<T>{},public class HashSet<E>{}T, E 只能是引用类型
在给泛型指定具体类型后, 可以传入该类型或者子类类型
//如果是这样写, 泛型默认是 Object ArrayList arrayList = new ArrayList();//等价于ArrayList<Object> arrayList = new ArrayList<Object>();
自定义泛型
- A后面泛型, 我们就把 A 称为自定义泛型类
- T,R,M泛型的标识符, 一般是单个大写字母
- 泛型标识符可以有多个
- 普通成员可以使用泛型 (属性, 方法)
- 使用泛型的数组, 不能初始化 (因为数组在 new 不能确定类型, 就无法在内存开空间)
- 静态方法中不能使用类的泛型(因为静态方法需要类加载, 类加载的时候不能确定类型)
自定义泛型接口
- 接口中, 静态成员也不能使用泛型
- 泛型接口的类型, 在继承接口或者实现接口时确定
- 没有指定类型, 默认为Object
自定义泛型方法
- 泛型方法, 可以定义在普通类, 也可以定义在泛型类
- 泛型方法被调用的时候类型就会确定, 当调用方法时, 传入参数, 编译器就会确定类型
public void eat(E e){}不是一个泛型方法, 儿是eat方法使用了类声明的泛型- 泛型方法, 可以使用类声明的泛型, 也可以使用自己声明的泛型
泛型的继承和通配符
- 泛型没有继承性
List<Object> list = new ArrayList<String> () //错误的
<?>表示支持任意类型<? extends A>表示支持A类及A类的子类, 规定了泛型的上限<? super A>表示支持A类以及A类的父类, 不限于直接父类, 规定了泛型的下限

